My hometown is a touristic island on the seaside near to the beach. There is only one bridge that connects it to the mainland, and it means that traffic is a nightmare during summer, with frequent and annoying jams.

Jam hours depend on a lot of circumstances (weekday, traffic flow dynamics, weather, etc) and they seem to be nearly unpredictable. Well, I felt that I had to do something about it. I wanted to know at least how much traffic there is now, if is increasing or not, and its typical variation within the day.
It was definitely a topic for a small passion project during work vacation, so I’ve built a small mobile app in Flask to help drivers understand whether or not put themselves on the road. I called it RomeaJam:
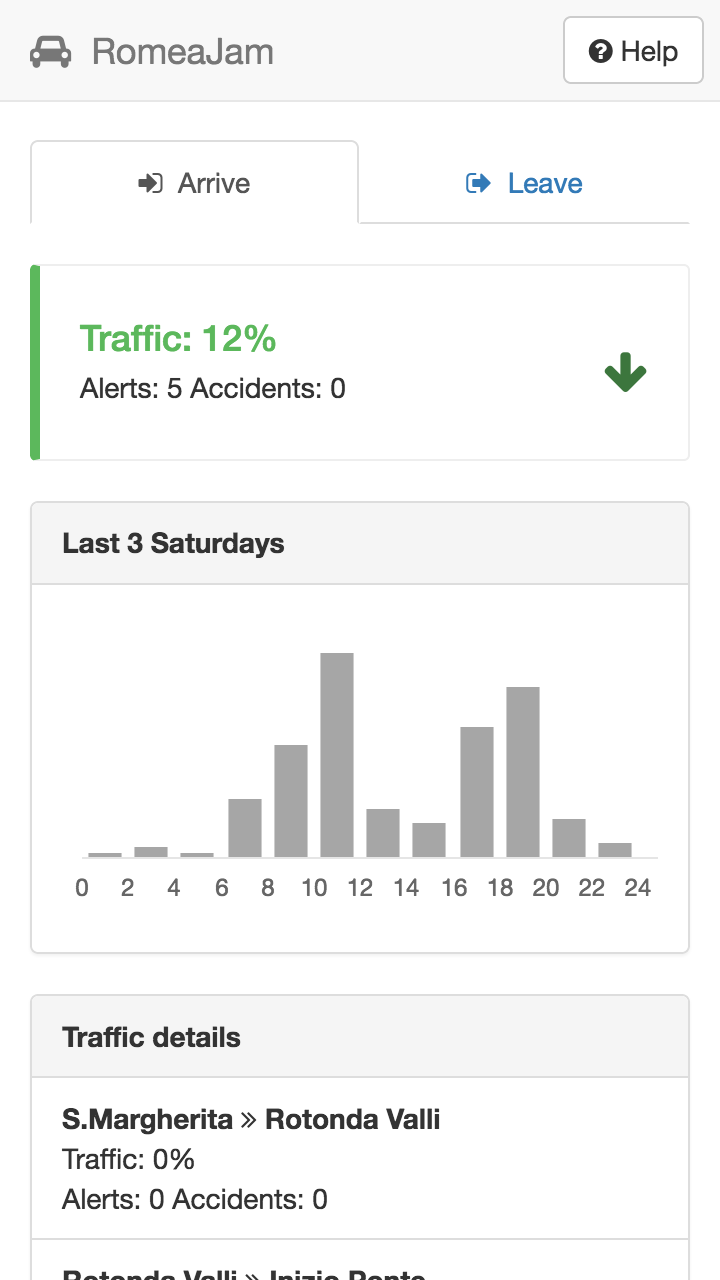
This little project led me to learn some cool Python stuff:
ORMs: SQLAlchemy was a revelation - I always desired an abstraction level that could handle classes without writing raw SQL!
Flask packages: Flask is growing very fast, and there is an ecosystem of packages for doing literally everything (scheduling jobs, manage SQLAlchemy, tracking app usage on the server side without cookies, etc)
Deploy Flask to production: I used apache2 with a python virtualenv, and I learned that it can be quite an hassle. I definitely have to try to dokerize it.
I’m also excited because in the next year I will have enough data for time series analysis and short term traffic predictions!
GitHub repository for this project
UPDATE (2016-11-05): The months passed and my MySQL database is still increasing (2M rows!). I learned that an index rebuild with mysqlcheck -Aa -uroot -p can speed up querying time, but still the webapp became very slow (expecially on query with joins). During the winter it’s not used, but in the next summer I will have to move old data to a different database, leaving only the last month available for the webapp.