In the last two weeks at the Metis Data Science Bootcamp we dived into NoSQL databases and natural language processing (week 7), unsupervised learning algorithms (week 7-8), dimensionality reduction, topic modeling and similarity (week 8), while working on an individual project: I choose to apply unsupervised learning techniques for clustering text data.
Firstly, I used the Pearson Kitchen Manager API for clustering almost 500 worldwide recipes basing on their ingredients. After applying several algorithms, I extracted the top keywords for some of the clusters and printed them in word clouds:
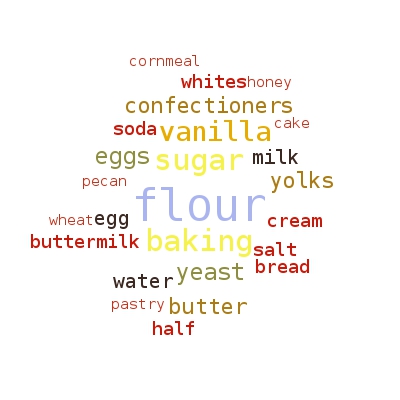
Secondly, I switched to the Yummly API for clustering ingredients on 17,000 Italian recipes from 1,000 blogs and kitchen websites. This time, the basic idea underneath ingredients clustering was to extract a bunch of not-too-rare and not-too-common ingredients, so I selected 71 ingredients with the help of a variance threshold. Then I built a relationship matrix between these ingredients using different scoring methods (jaccard similarity, joint probability score, etc). After trying some combinations of clustering algorithms and input matrices, I put one of the results in this d3 visualization:

As we should expect, items like (yeast, flour, milk) or (mozzarella, tomato sauce, pizza doughs) are grouped together, and the clusters themselves can help while compiling a shopping list.
At the end, I learned that tuning a clustering algorithm is more an art than a science: you need to explore not conventional approaches and combine different techniques basing on your intuition and the specific question you are trying to answer.