As always when you are experiencing a “flow condition”, I didin’t realized that the Metis Data Science Bootcamp came to an end. During these intense weeks we deepened our knlowledge of statistics and machine learning, as well as design and data visualization, in a way that surely I wasn’t expecting at the beginning.
In the last 4 weeks we covered “Big Data” topics like Hadoop, MapReduce, Hive, etc, while focusing on a final passion project. I worked on the design and development of a collaborative-filtering recommendation engine for restaurants based on user reviews.
Scraping framework: I used Scrapy and Splash for rendering and sraping almost one million reviews of NYC restaurants. I found Scrapy a very robust and powerful tool for scraping, since it can manage concurrent requests and it can be easily integrated with javascript renderers like Splash.
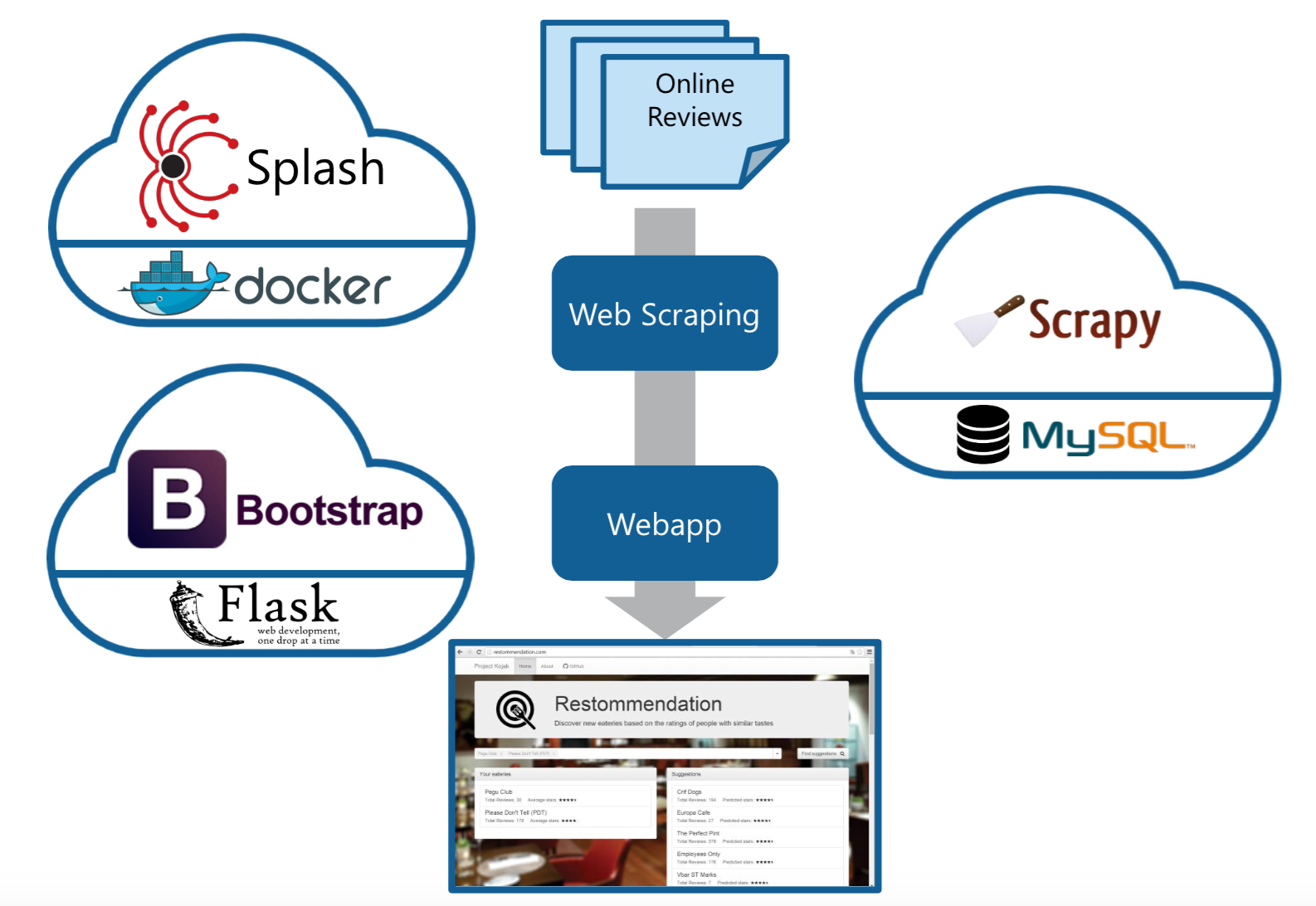
The basic idea underneath the collaborative-filtering model is to look for similar users, find the restaurants that they liked and rank them.
Similar users: after feature selection (I considered only restaurants and users with at least 5 reviews) and dimensionality reduction (using the IncrementalPCA in the last version of sklearn - 0.16), I got a dense matrix in which similar users can be found with a nearest neighbors algorithm, using a correlation distance metric (it permits to take in account different scoring attitudes between users, e.g. one user may give only scores from 3 to 5 stars and another only from 2 to 4).
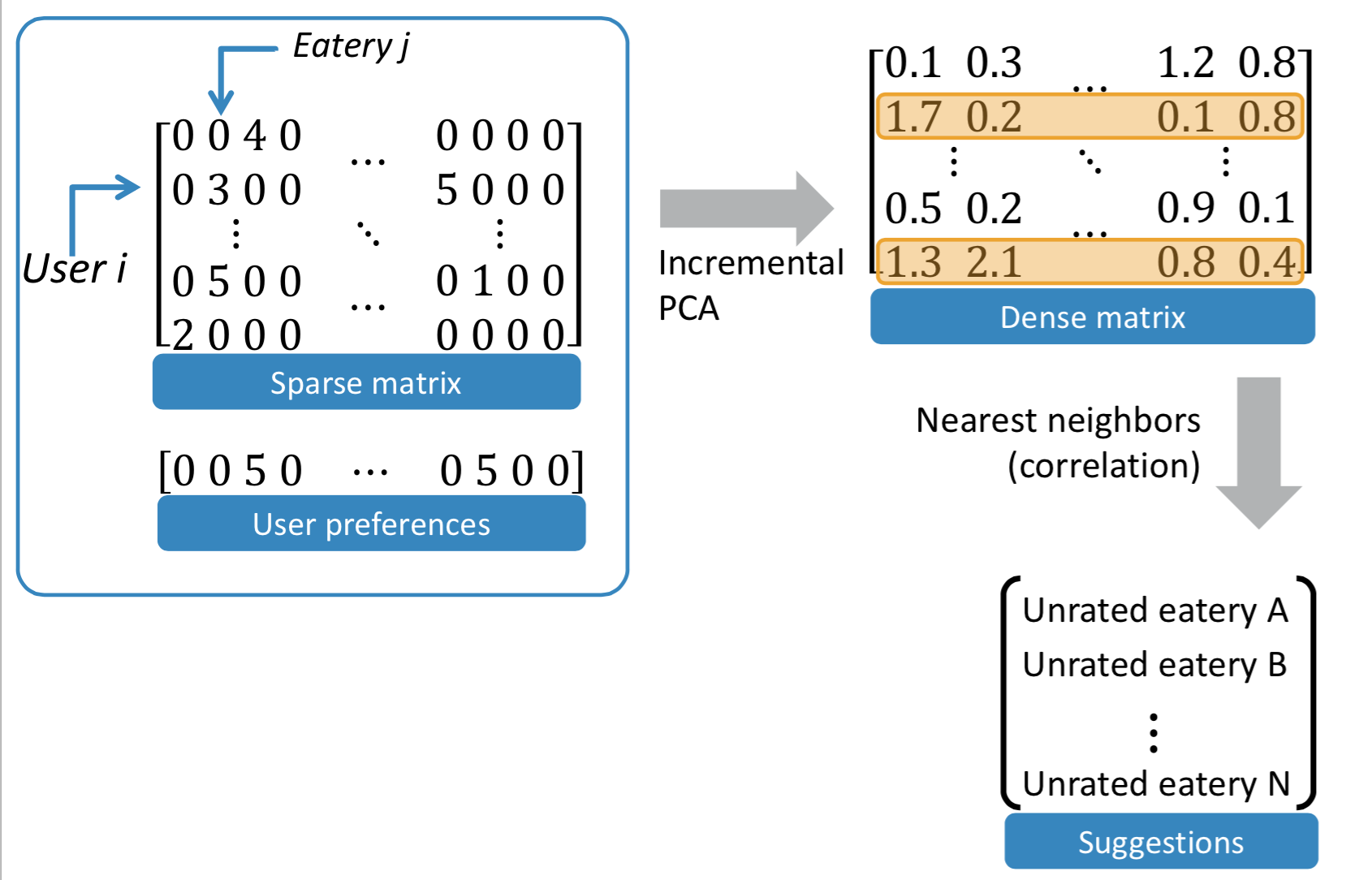
Recommendations: after getting the list of restaurants visited by the similar users, I developed a scoring method for preticting the number of stars. Based on a bayesian approach, it consists basically in updating a prior containing the overall stars smoothed by the total number of reviews for the restaurant with a posterior, i.e. the weighted average of the reviews of the similar users (where the weight takes in account the number of restaurants in common, the total reviews of the user and his number of helpful votes received).
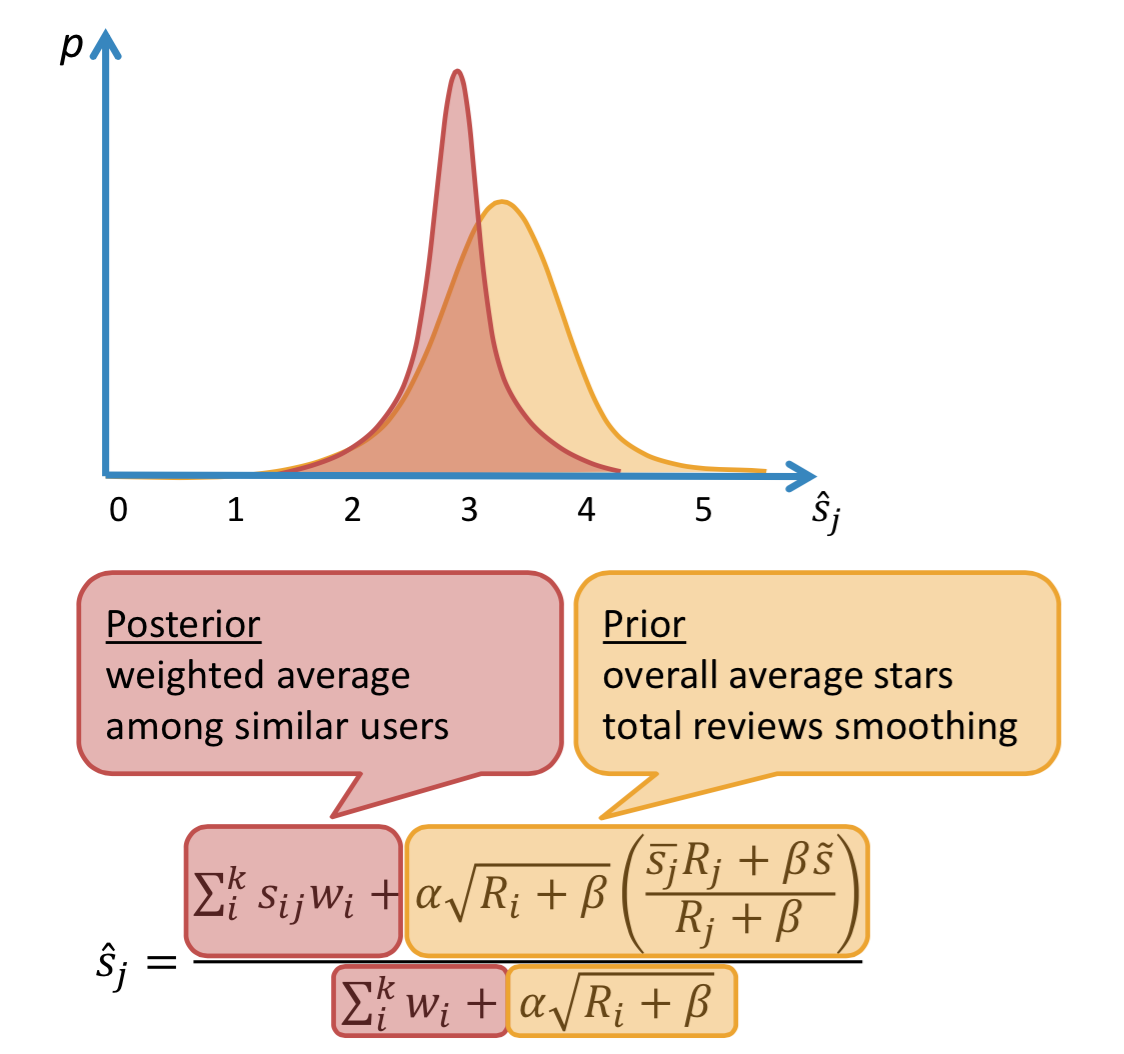
The main tuning parameters of the model are k (the number of nearest users to consider), alpha (how many additional users to include in the prior) and beta (how many reviews a restaurant must have in order to consider the overall average stars reliable).
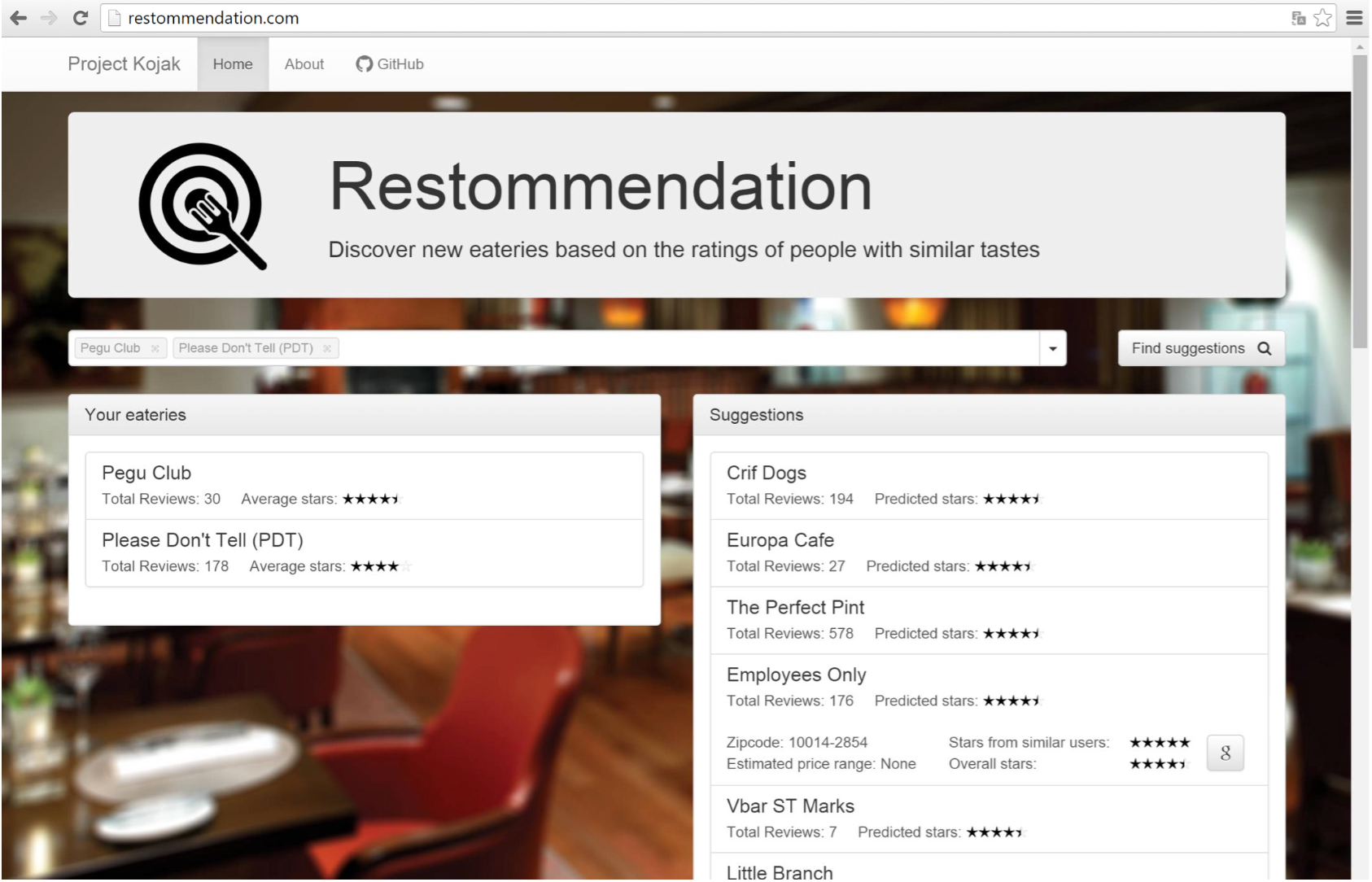
User interface: Afer tuning the model, I created a web application using Flask, Boostrap and other javascript packages like json2html, magicsuggest and multiselect. While I already used Flask in a previous project, Bootstrap was a very nice surpise: it’s modern, clean and easy to use - all features that makes it an ideal choice for rapid prototyping.
Here is the final version of the webapp: www.restommendation.com
As next steps, I will try to make the app available also for other cities, as well as creating an online-training mechanism for improving the recommendations (like/don’t like buttons).